Per semantica si intende una specifica del linguaggio che permette la comprensione del significato preciso delle parole.
Il web semantico è un particolare modo di "scrivere" le pagine web che permette ai crawler dei motori di ricerca di comprendere meglio le informazioni in esse contenute.
I dati strutturati sono lo strumento utile a raggiungere lo scopo.
Cosa sono i dati strutturati
Tutto ha inizio quasi 10 anni fa, nel 2011, quando i principali motori di ricerca Google, Bing e Yahoo! uniscono le forze per dare vita a schema.org, un progetto che ha come missione la creazione, il mantenimento e la promozione di schemi per dati strutturati su Internet, sulle pagine web, nei messaggi di posta elettronica, ecc.
HTML5 permette l'espansione del suo core set con l'aggiunta di vocaboli personalizzati, tramite appunto i microdati, che forniscono al motore di ricerca informazioni aggiuntive sulla risorsa.
I dati strutturati, nel senso più generale del termine, organizzano le informazioni di una pagina web con lo scopo di farle riconoscere al motore di ricerca.
Google potrà usare queste informazioni per arricchire i suoi risultati di ricerca generando così, il così detto, rich snippet).
Sia chiaro, Google può estrarre le informazioni in autonomia, ma l'uso dei dati strutturati ci permette di aiutare Google a comprendere meglio il contenuto. Questo ci porterà ad ottenere un risultato di ricerca più ricco.
I rich snippet non sono un fattore di ranking, ma, se usati bene, permettono un aumento del CTR (rapporto tra impressioni e clic del risultato di ricerca, dove le impressioni sono le volte in cui la tua pagina web compare sui motori di ricerca e il clic, beh... è il clic) il quale ricordo essere un fattore di ranking.
Ma prima di iniziare a buttare dati strutturati a caso nelle pagine web è necessario comprenderli e dove potrà mai essere il punto di partenza? Rullo di tamburi al contrario.... è ovvio, dalla documentazione!
La documentazione ufficiale
Chi mi conosce sa quanto per me sia importante leggere la documentazione, soprattutto se sono scritte bene.
Per quanto riguarda i dati strutturati ci sono un paio di fonti da consultare, il sito ufficiale schema.org e developers.google.com nella sezione "Ricerca".
schema.org
Di per sé non è un granché, è abbastanza scarna, ma comunque utile per capire la quantità impressionante di informazioni che possiamo fornire per arricchire di significato le nostre pagine web.
La reference è sufficientemente completa riguardo al tipo di dato che ogni proprietà richiede per essere impostata correttamente.
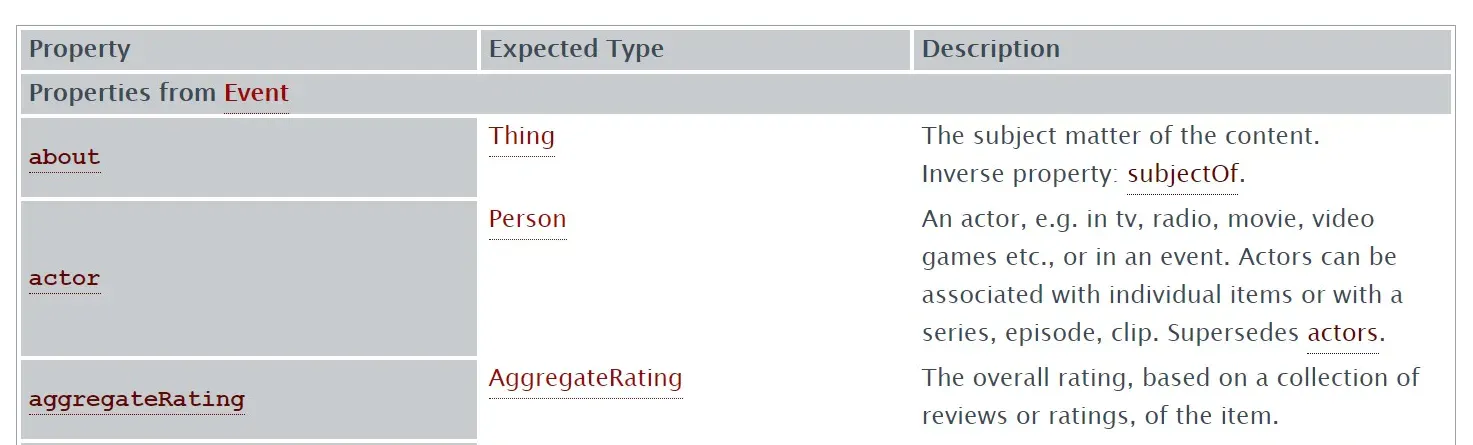 Le proprietà dello schema Event
Le proprietà dello schema Event
Dall'immagine riporto le prime tre proprietà di Event. Possiamo vedere che about, actor e aggregateRating si aspettano un particolare tipo di dato, il quale fa riferimento ad un altro schema, rispettivamente Thing (cose/oggetti), Person (persone), AggregateRating (valutazioni/recensioni).
Gli schemi a loro volta hanno delle specifiche, come visibile qui di seguito:
 Le proprietà dello schema Thing
Le proprietà dello schema Thing
Questa è la vera utilità di schema.org. Ci sono altre informazioni come ad esempio implementare gli schemi tramite microdati in HTML, ma per avere una panoramica più completa e dettagliata sulle modalità di implementazione la risorsa di riferimento rimane Google, il quale mostra l'implementazione in JSON-LD (quella consigliata) e le principali categorie di schema accettate.
developers.google.com
La documentazione di Google nella sezione specifica per la ricerca mette a disposizione una miriade di guide, approfondimenti e casi di studio che fanno sembrare la SEO un gioco da ragazzi.
Per trovare le informazioni relative ai dati strutturati bisognerà andare nella sezione Guide e andare nella sezione "Attiva i risultati multimediali con i dati strutturati" nella colonna di sinsitra.
Il consiglio rimane di leggersi tutto, ma a grandi linee: scoprire come funzionano i dati strutturati, linee guida generali e la galleria offrono già una tonnellata di informazioni in più da unire a quelle trovate su schema.org
Sì ok tutto molto bello, ma esattamente come li usa Google?
A cosa servono e come li usa Google
Ormai è chiaro che i dati strutturati servono ad arricchire le pagine web di informazioni utili al crawler per poter arricchire a sua volta i risultati di ricerca creando i rich snippet, ma come esattamente?
Sempre più ricerche vedono la comparsa dei rich snippet, questi risultati di ricerca con più informazioni rispetto al classico URL, Titolo e Descrizione. Si presentano sotto forma di date di pubblicazione, valutazione in stelline, chilocalorie e il tempo di cottura di un piatto o addirittura intere ricette da seguire passo passo.
Prima però facciamo un passo indietro e cerchiamo di capire meglio il quadro generale e cosa sta facendo Big G.
Google è nato nel 1997 come motore di ricerca, rivoluzionando completamente ciò che già c'era. Tramite la qualità dei suoi risultati è riuscito a costruire un enorme fiducia nei confronti dei suoi utenti, quasi da rendere superflui tutti i risultati dalla seconda pagina in poi. Di fatto troviamo ciò che cerchiamo nelle prime dieci posizioni, soprattutto nelle prime tre.
In base ai dati raccolti, i siti web si devono evolvere per soddisfare le esigenze dei propri utenti. Google, prima di tutto, è un sito web ed è quindi soggetto alle stesse regole.
Da tempo Google ha iniziato una transizione da motore di ricerca a motore di risposta, perché è quello che cerchiamo, risposte.
Per perseguire questo obiettivo sono state e verranno introdotte pesanti rivoluzioni come le pagine a 0 risultati, dove l'unica risposta sarà quella fornita da Google (es. che ore sono a Sydney). Oppure, i risultati zero che estraggono informazioni dalle pagine web e le usano per poter generare risposte immediate che l'utente poi potrà scegliere di approfondire oppure ritenersi soddisfatto e continuare a cercare o andarsene, senza visitare il sito web.
Ammettiamolo, la qualità del web è peggiorata tantissimo. Siti lenti, user experience pessima, banner di ogni tipo da chiudere, richieste di notifiche da disabilitare, banner pubblicitario da nascondere e video da silenziare sono solo alcuni delle problematiche e Google vuole fare qualcosa. Tra le varie soluzioni c'è anche quella di non far arrivare l'utente sul sito perché intercettato in precedenza dalla risposta del motore di ricerca.
In tutto questo però non stiamo tenendo in considerazione una cosa, la ricerca vocale. Quella ricerca dove non abbiamo nessuna interfaccia grafica, ma solo il nostro assistente che ascolta la nostra richiesta e ci fornisce la risposta che secondo lui è più attinente.
Google ha messo il suo assistente ovunque, sul nostro telefono, nelle smart tv di ultima generazione e nelle nostre case con i dispositivi Nest (Mini, Hub, Tv, ecc.) tutti integrati perfettamente con dispositivi IoT sparsi per la casa come lampade, la tv menzionata in precedenza, serrature delle porte, cucine, frigoriferi e chi più ne ha più ne metta.
Momento momento momento, ma in tutto questo cosa c'entrano i dati strutturati? Prima ho detto che possono essere usati per mostrare l'intera esecuzione di una ricetta passo passo. Vogliamo provare?
"Hey Google come si cucinano gli spaghetti allo scoglio?"
Uhm... da smartphone solo un elenco di ricette, da Nest Mini idem, ma è su Nest Hub che tutto cambia.
Ci verrà chiesto di scegliere dalla stessa lista di ricette viste sullo smartphone, ma non si collegherà al sito web, ci leggerà passo a passo gli step da seguire e dove pensate abbia recuperate questo informazioni? Ma è ovvio dai dati strutturati del sito che avete scelto dalla lista di ricette.
Fantastico! Ma come si implementano? Talk is cheap, show me the code. È tempo di aprire il nostro editor.
Come si implementano (codice)
I dati strutturati possono essere implementati con:
Nei prossimi paragrafi li vedremo più nel dettaglio.
Microdati
I microdati sono una specifica dell'HTML che annida i dati strutturati all'interno del contenuto HTML stesso. Attraverso l'uso degli attributi si *tagga *il testo con la proprietà che si desidera esporre. Ciò implica che il contenuto debba essere visibile in pagina.
Prendiamo come esempio questo snippet di codice:
1<div>
2 <h1>The Batman</h1>
3 <span>Regista: Matt Reeves (nato il 27 aprile 1966)</span>
4 <span>Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html">Trailer</a>
6</div>Il markup per noi parla chiaro, per i motori di ricerca un po' meno. Con i microdati possiamo arricchire il codice affinché il crawler possa capire a sua volta che stiamo parlando del film "The Batman"
itemscope e itemtype
La prima cosa da fare è identificare l'area dove sono contenute le informazioni e contrassegnarla con l'attributo itemscope:
1<div itemscope>
2 <h1>The Batman</h1>
3 <span>Regista: Matt Reeves (nato il 27 aprile 1966)</span>
4 <span>Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html">Trailer</a>
6</div>In questo modo dichiariamo che quello specifico <div> contiene informazioni relative ad uno specifico elemento.
Da solo però, itemscope non ha molto senso e non aiuta, bisogna esplicitare che ciò che è contenuto nel div è un film, come definito nella gerarchia dei tipi di schema.org.
Per farlo dobbiamo usare itemtype, il quale come valore accetta un URL, quello dove risiede la specifica del tipo, in questo caso http://schema.org/Movie.
1<div itemscope itemtype="http://schema.org/Movie">
2 <h1>The Batman</h1>
3 <span>Regista: Matt Reeves (nato il 27 aprile 1966)</span>
4 <span>Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html">Trailer</a>
6</div>Questo è sufficiente? No. In base al markup a disposizione possiamo dare altre informazioni in merito al film, nello specifico: titolo, regista, genere e trailer.
Per etichettare le proprietà di un elemento si usa l'attributo itemprop, seguito dal nome della proprietà, i quali non sono di fantasia, ma quelli specificati in schema.org, nel nostro caso specifico: name, director, genre e trailer.
1<div itemscope itemtype="http://schema.org/Movie">
2 <h1 itemprop="name">The Batman</h1>
3 <span
4 >Regista: <span itemprop="director">Matt Reeves</span> (nato il 27 aprile
5 1966)</span
6 >
7 <span itemprop="genre">Drammatico/giallo</span>
8 <a href="../movies/the-batman-trailer.html" itemprop="trailer">Trailer</a>
9</div>Com'è possibile notare abbiamo dovuto aggiungere un elemento span extra che ci permettesse di etichettare esclusivamente il nome e il cognome del regista. Essendo un elemento inline (può essere affiancato ad altri), <span> non modifica il modo in cui verrà renderizzata la pagina e questo lo rende l'elemento ideale per usare itemprop.
A questo punto i motori di ricerca capiranno meglio ciò che inizialmente era comprensibile solo per noi esseri umani.
Nidificare gli elementi
Prima di passare oltre, bisogna sapere che può capitare che il valore di una proprietà sia a sua volta un elemento, come nel nostro caso lo può essere il regista. Oltre ad essere il regista di un film, Matt Reeves è anche una persona. Se volessimo quindi arricchire ulteriormente il nostro markup dovremmo modificarlo come segue:
1<div itemscope itemtype="http://schema.org/Movie">
2 <h1 itemprop="name">The Batman</h1>
3 <span itemprop="director" itemscope itemtype="http://schema.org/Person"
4 >Regista: <span itemprop="name">Matt Reeves</span> (nato il
5 <span itemprop="birthDate">27 aprile 1966</span>)</span
6 >
7 <span itemprop="genre">Drammatico/giallo</span>
8 <a href="../movies/the-batman-trailer.html" itemprop="trailer">Trailer</a>
9</div>RDFa
Gli RDFa sono un'estensione dell'HTML5 che supporta i dati strutturati e mette a disposizione nuovi attributi che permettono di arricchire la pagina web. Questo implica che come per i microdati anche i contenuti etichettati con gli attributi RDFa debbano essere presenti in pagina.
Prendiamo in considerazione lo snippet visto nei paragrafi precedenti:
1<div>
2 <h1>The Batman</h1>
3 <span>Regista: Matt Reeves (nato il 27 aprile 1966)</span>
4 <span>Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html">Trailer</a>
6</div>Microdati e RDFa si assomigliano parecchio, soprattutto dopo gli ultimi aggiornamenti di quest'ultimo che l'hanno allineato parecchio alla sua, più popolare, alternativa.
Per iniziare dobbiamo procedere come prima, identificando l'area che vogliamo arricchire, ma invece di itemscope e itemtype useremo vocab e typeof.
vocab e typeof
L'attributo vocab contiene l'URL del vocabolario da utilizzare, mentre typeof possiamo definirlo come la definizione che vogliamo leggere all'interno del suddetto vocabolario.
Il nostro snippet aggiornato sarà:
1<div vocab="http://schema.org/" typeof="Movie">
2 <h1>The Batman</h1>
3 <span>Regista: Matt Reeves (nato il 27 aprile 1966)</span>
4 <span>Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html">Trailer</a>
6</div>Come per i microdati, questi due attributi sono insufficienti, bisogna definire le varie proprietà. Mentre con i microdati usiamo itemprop, in RDFa l'attributo da usare è property. I valori, usando schema.org, sono i medesimi di prima. Per cui il nostro snippet cambierà come segue:
1<div vocab="http://schema.org/" typeof="Movie">
2 <h1 property="name">The Batman</h1>
3 <span>Regista: <span property="director">Matt Reeves (nato il 27 aprile 1966)</span>
4 <span property="genre">Drammatico/giallo</span>
5 <a href="../movies/the-batman-trailer.html" property="trailer">Trailer</a>
6</div>Nidificare gli elementi
A questo punto abbiamo la nostra scheda del film comprensibile sia per gli esseri umani che per il crawler. Possiamo fare qualcosina in più? Come visto in precedenza con i microdati anche RDFa permette la nidificazione di altri elementi. Come prima quindi andremo ad inserire una nuova entità Persona per arricchire ulteriormente la parte relativa al regista del film.
1<div vocab="http://schema.org/" typeof="Movie">
2 <h1 property="name">The Batman</h1>
3 <span property="director" typeof="Person"
4 >Regista: <span property="name">Matt Reeves</span> (nato il
5 <span property="birthDate">27 aprile 1966</span>)</span
6 >
7 <span property="genre">Drammatico/giallo</span>
8 <a href="../movies/the-batman-trailer.html" property="trailer">Trailer</a>
9</div>Come possiamo osservare non è stato necessario ridefinire il vocab o un nuovo scope, ma è stato sufficiente utilizzare nuovamente l'attributo typeof per comunicare che il contenuto dello span è di tipo Person.
JSON-LD
JSON è una notazione JavaScript, acronimo di JavaScript Object Notation, l'estensione LD sta per Linked Data. Si tratta quindi di una porzione di codice da includere nel tag <script> nell'intestazione (la head) o nel corpo (il body) del documento. A differenza dei microdati e di RDFa i dati esposti non devono essere per forza visibili in pagina e l'implementazione non implica un'intervento massivo nel codice della pagina web. JSON-LD è il formato consigliato da Google.
Il codice visto finora quindi non dovrà più essere interpolato nell'HTML esistente, ma si tratterà semplicemente di uno script simile a questo:
1{
2 "@context": "http://schema.org/",
3 "@type": "Movie",
4 "name": "The Batman",
5 "director": {
6 "@type": "Person",
7 "name": "Matt Reeves",
8 "birthDate": "27 aprile 1966"
9 },
10 "genre": "Drammatico/giallo",
11 "trailer": "../movies/the-batman-trailer.html"
12}Questo è l'esempio completo con la nidificazione di un'altra entità, ma andiamo con ordine:
- Le parentesi graffe identificano un oggetto (Object Notation)
@contextè l'equivalente divocabvisto negli RDFa dove definiremo il contesto principale@typeè l'equivalente ditypeofvisto negli RDFa dove definiremo il tipo specifico di contesto- Le altre proprietà sono sempre le stesse ma scritte rispettando la notazione prevista da JSON.
Per quanto concerne la nidificazione di altre entità è necessario aprire una nuova coppia di parentesi graffe (un nuovo oggetto) riportando la tipologia (Person) e far seguire le proprietà che descrivono l'entità.
Quando usare un nuovo oggetto e quando del normale testo?
Se nella colonna Expected Type vediamo altre entità significa che il valore atteso deve essere un nuovo oggetto di tipo Thing, piuttosto che Person o AggregateRating.
Mentre se il tipo richiesto è del semplice testo o un URL basterà aprire le virgolette e riportare il valore desiderato come fatto per le proprietà name, genre, trailer, ecc.
Come riportato all'inizio di questo paragrafo le informazioni non devono essere per forza in pagina, quindi possiamo arricchire il nostro JSON con nuove informazioni senza dover prevedere ampliamenti del nostro layout. Un esempio di JSON-LD completo relativo ad un film potrebbe assomigliare a questo:
1{
2 "@context": "http://schema.org/",
3 "@type": "Movie",
4 "name": "The Batman",
5 "description": "Nel suo secondo anno come vigilante, Batman si confronta con la corruzione dilagante di Gotham City e sui collegamenti che questa ha con la sua famiglia, oltre a entrare in conflitto con un serial killer noto come l'Enigmista.",
6 "director": {
7 "@type": "Person",
8 "name": "Matt Reeves",
9 "birthDate": "27 aprile 1966"
10 },
11 "image": "../movies/the-batman-locandina.jpg",
12 "dateCreated": "2020-10-11",
13 "genre": "Drammatico/giallo",
14 "trailer": {
15 "@type": "VideoObject",
16 "name": "The Batman Primo Trailer",
17 "description": "Trailer di The Batman presentato al DC FanDom del 2020",
18 "thumbnailUrl": "../movies/the-batman-trailer-thumbnail.jpg",
19 "contentUrl": "../movies/the-batman-trailer.html",
20 "uploadDate": "2020-10-11"
21 }
22}Come possiamo osservare ho usato nuove informazioni che nel nostro markup non erano presenti, ma che possono servire al crawler per comprendere meglio di che cosa stiamo parlando. I nomi delle proprietà e i relativi valori sono stati presi dalla documentazione presente su schema.org.
Ma quindi quale scelgo?
Google consiglia di usare JSON-LD perché, presumo, sia più veloce da leggere ed è meno soggetto ad errori rispetti alle altre due alternative.
Personalmente uso JSON perché stracomodo lato sviluppo. Il markup visto negli esempi era semplice, ma in una situazione reale le cose sono molto più complesse, ci sono altri attributi con la quale fare i conti e la leggibilità è la prima a farne le spese.
In ottica di manutenibilità del codice preferisco separare il markup dai dati strutturati prediligendo uno script piuttosto che l'interpolazione qui e là.
Come si implementano in WordPress
Chi programma può benissimo scrivere qualche funzione extra direttamente nel functions.php del tema in uso e aggiungere i dati strutturati direttamente nella head sfruttando l'aggancio wp_head messo a disposizione da WordPress.
In pratica la funzione è così strutturata:
- Recupero tutte le informazioni relative alla pagina web (es. un articolo del blog) attraverso le opportune funzioni
- Inserire le informazioni recuperate all'interno del JSON (magari usando la sintassi heredoc invece di tantissimi
echooprintf) - Stampare la stringa ottenuta, la quale verrà inserita in base all'aggancio scelto
wp_head,wp_footer,wp_ovunque_tu_voglia, ecc.
1<?php
2add_action( 'wp_head', 'mr_generate_schema' );
3
4function mr_generate_schema() {
5
6 if ( ! is_single() )
7 return;
8
9 // TODO: Recuperare tutte le informazioni necessarie relative al post.
10
11 $schema = <<<SCHEMA
12 <script type="application/ld+json">
13 {
14 "@context": "https://schema.org",
15 "@type": "Article",
16 "headline": "$qui_va_il_titolo",
17 "alternativeHeadline": "$qui_va_il_riassunto",
18 "image": "$qui_va_la_thumbnail",
19 "author": "$qui_va_l_autore",
20 "genre": "$qui_va_la_categoria",
21 "publisher": {
22 "@type": "Organization",
23 "name": "$qui_va_il_nome_del_sito",
24 "logo": {
25 "@type": "ImageObject",
26 "url": "$qui_va_il_logo_del_sito"
27 }
28 },
29 "url": "$qui_va_l_url_dell_articolo",
30 "mainEntityOfPage": {
31 "@type": "WebPage",
32 "@id":"$qui_va_l_url dell articolo"
33 },
34 "datePublished": "$qui_va_la_data_di_pubblicazione",
35 "dateCreated": "$qui_va_la_data_di_creazione",
36 "dateModified": "$qui_va_la_data_di_modifica",
37 "description": "$qui_va_il_riassunto"
38 }
39 </script>
40 SCHEMA;
41
42 echo $schema;
43
44}Ma il codice non è completo!?! Troppo facile... Prova a completarlo e vediamo come te la cavi, devi solo leggere la documentazione di WordPress e usare le giuste funzioni per recuperare le informazioni richieste.
Chi invece, non ha tempo, non ha voglia di sbattere la testa sullo script incompleto qui sopra, non ha qualcuno di competente che gli gestisce il sito o preferisce ripiegare sull'installazione di un plugin ricordo che Yoast fa già un gran bel lavoro, ma ci sono anche altre alternative come Rank Math e All In One SEO che danno soddisfazioni, anche se Yoast rimane un'ottima soluzione per via dei suoi molteplici anni di esperienza.
Controllare la validità
Per controllare la validità dei dati strutturati si può usare lo strumento di "Test dei risultati multimediali" messo a disposizione da Google.
Lo strumento ci chiederà se vogliamo recuperare una pagina web o incollare del codice e questa scelta dipende ovviamente da cosa vogliamo testare.
Se dovessimo testare lo snippet JSON del film "The Batman" ci basterà incollare il codice nell'apposita casella ed eseguire l'analisi. Dopo qualche secondo lo strumento ci restituirà una pagina come questa:
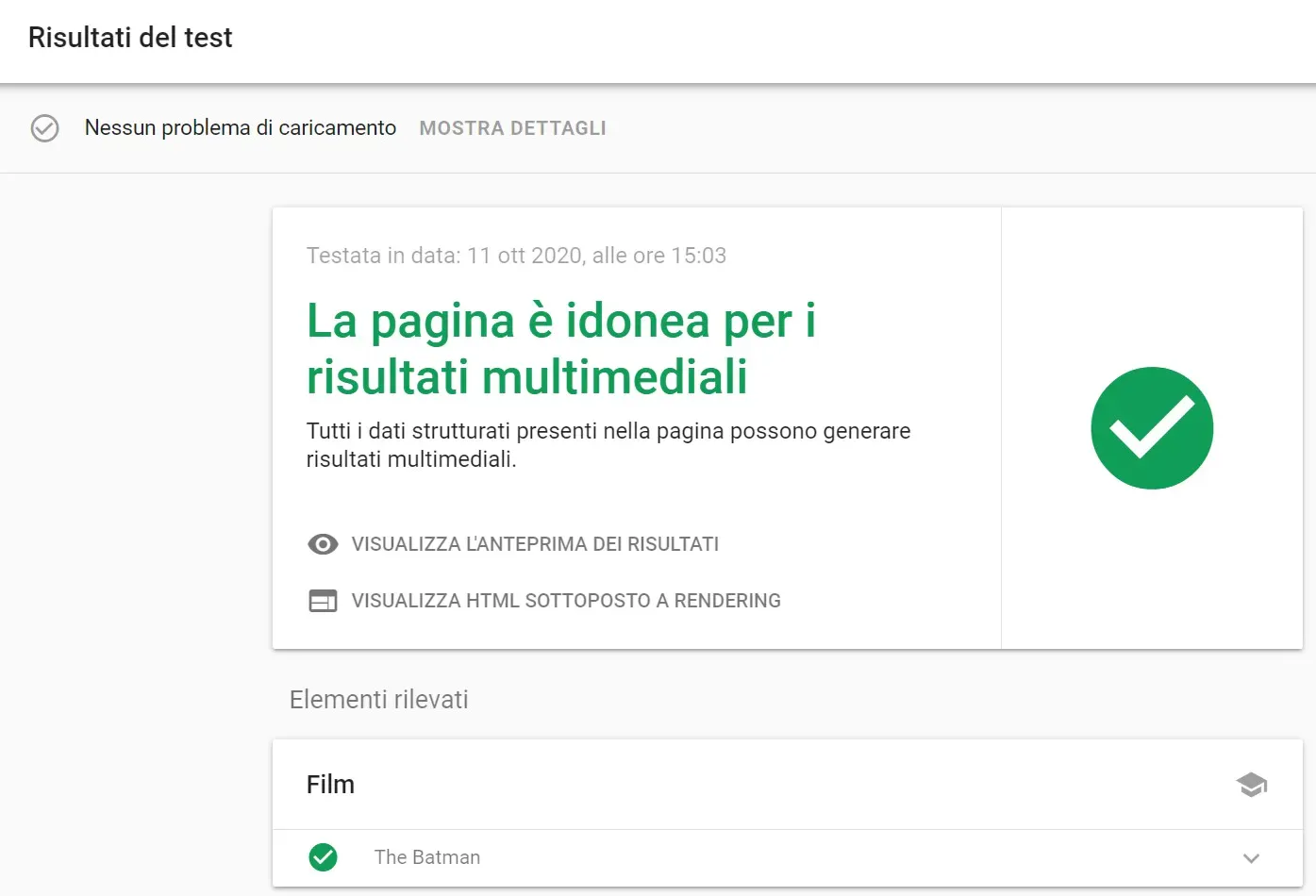
I dati strutturati relativi al film "The Batman" sono stati implementati e recuperati con successo. Espandendo la sezione vedremo i vari dati passati.
Se invece qualcosa dovesse andare storto (ho rimosso delle virgolette) lo strumento ci indicherà l'errore di analisi.
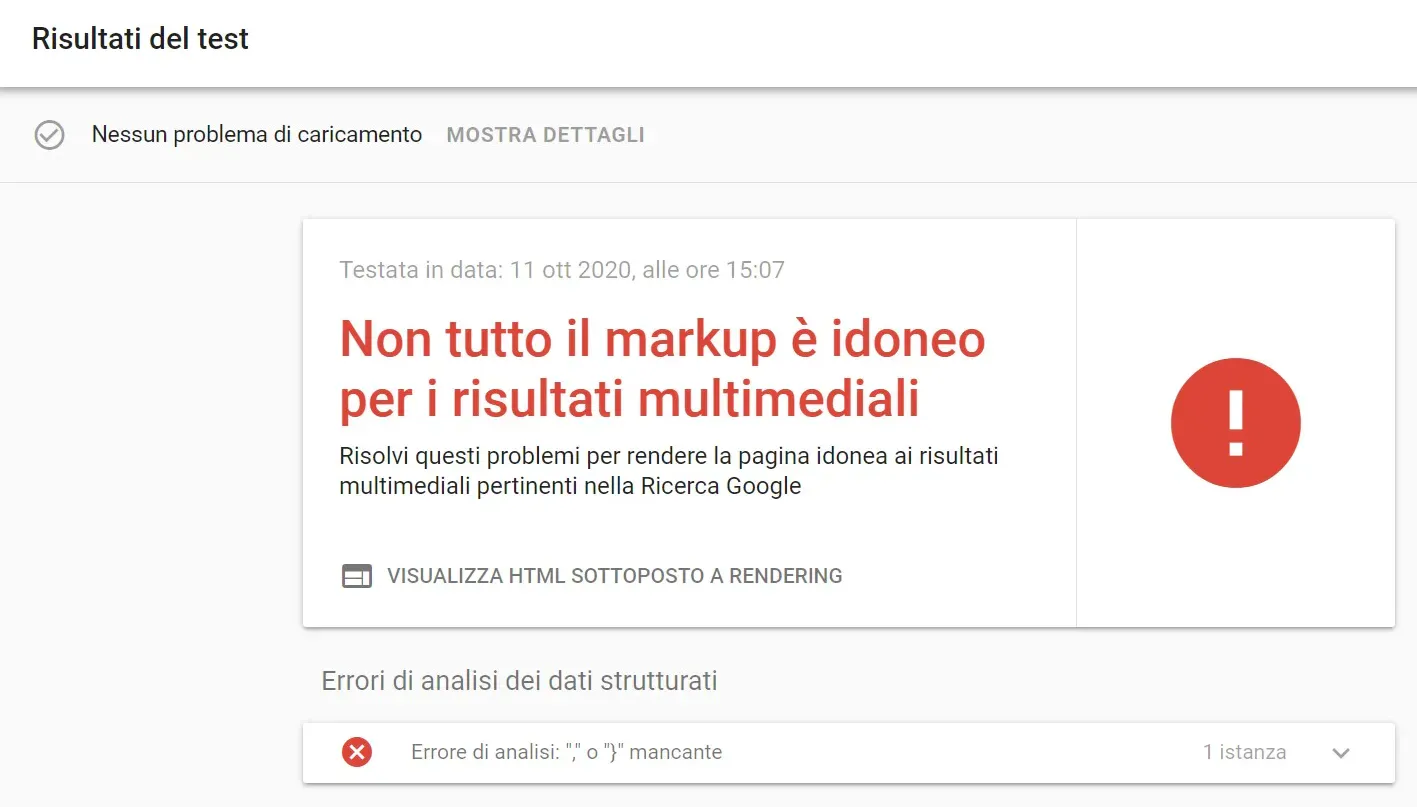
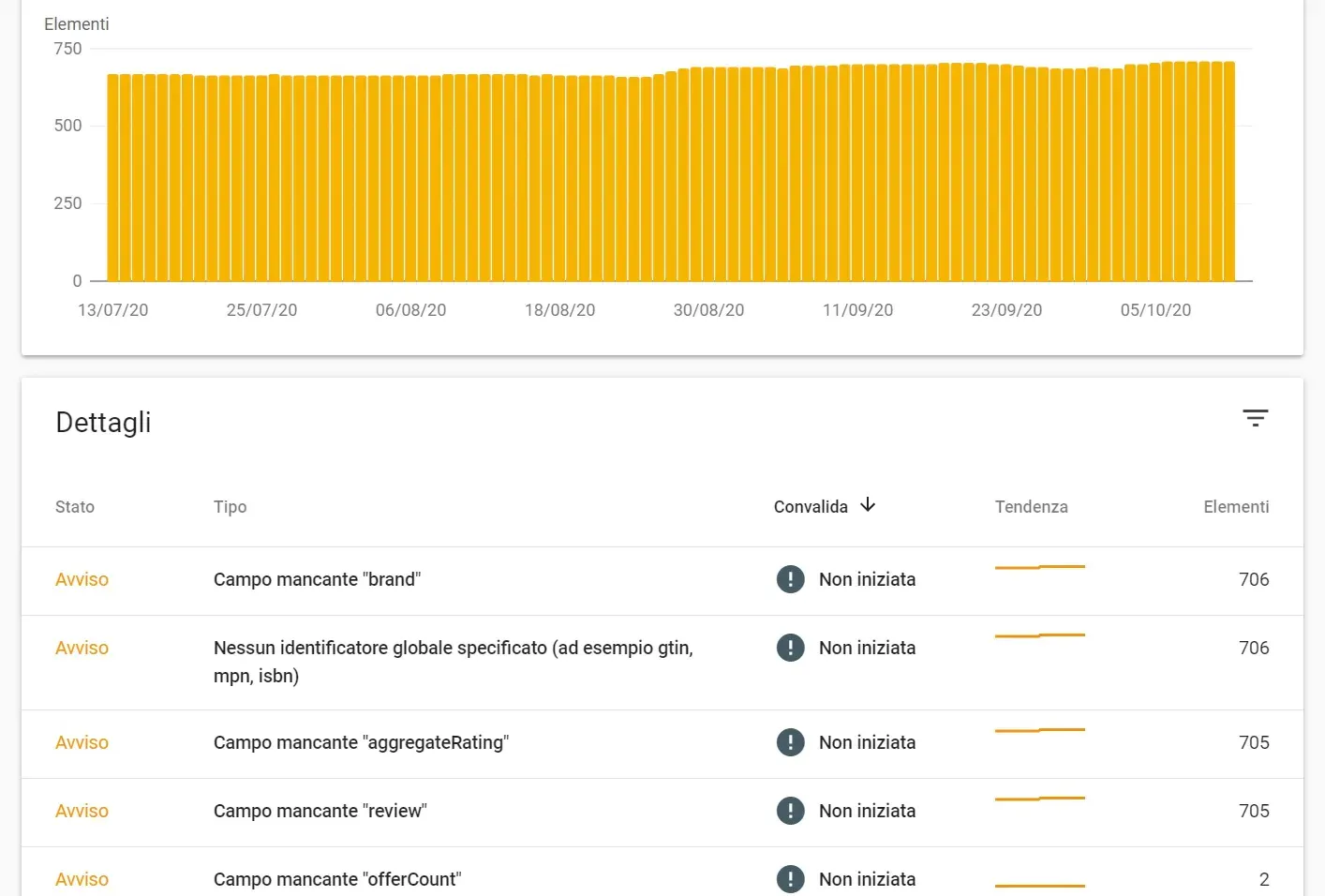
Infine, nel caso di errori meno gravi (campo facoltativo mancante) ci mostrerà un avviso, mentre se a mancare sono delle proprietà obbligatorie ci mostrerà degli errori, indicando quali proprietà mancano all'appello.
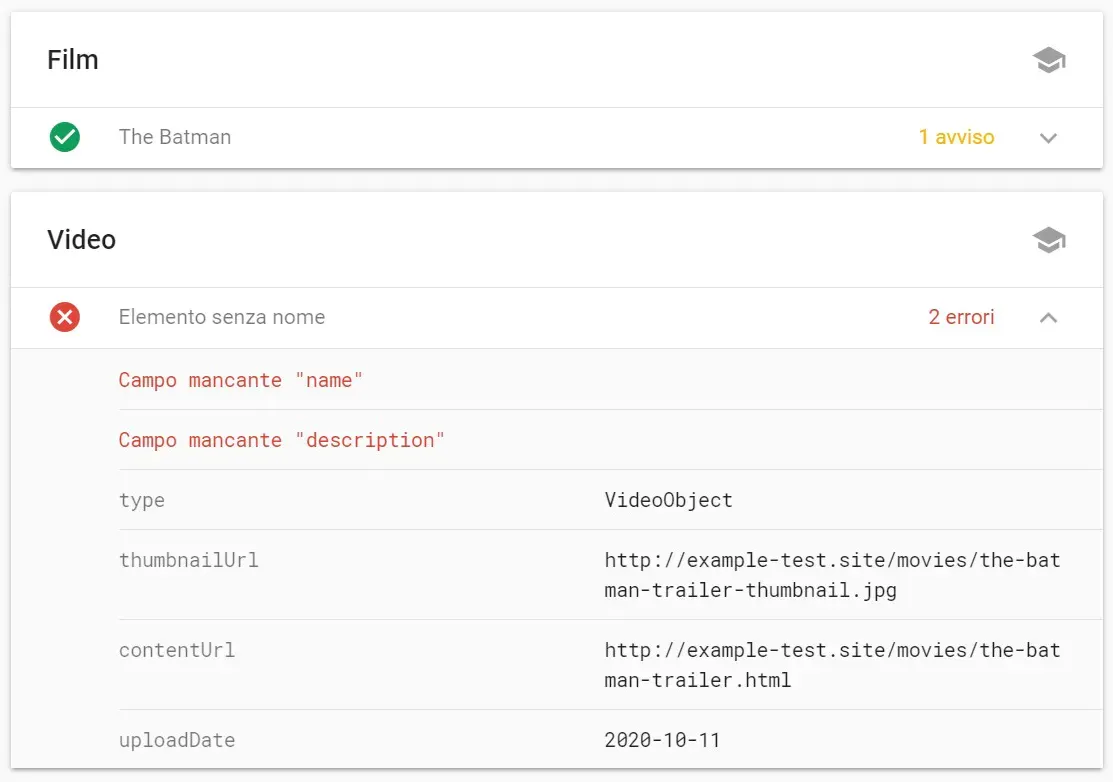
Individuare eventuali problemi
Per quanto le cose possano funzionare correttamente all'inizio, non è detto che il codice rimanga valido nel tempo. C'è quindi la necessità di monitorare nel tempo i nostri dati strutturati.
Per poter svolgere questo compito il nostro alleato è ancora una volta Google con la sua Search Console.
Verificando la proprietà su Search Console abbiamo a disposizione svariati strumenti tra cui quelli relativi ai dati strutturati, per la quale ci vengono indicati gli errori, avvisi o se tutto è ok.
Ad esempio, questo è un grafico dei dati strutturati relativi alla casella di ricerca sitelink, quel particolare tipo di dato strutturato che attiva la casella di ricerca subito sotto al nome del sito.
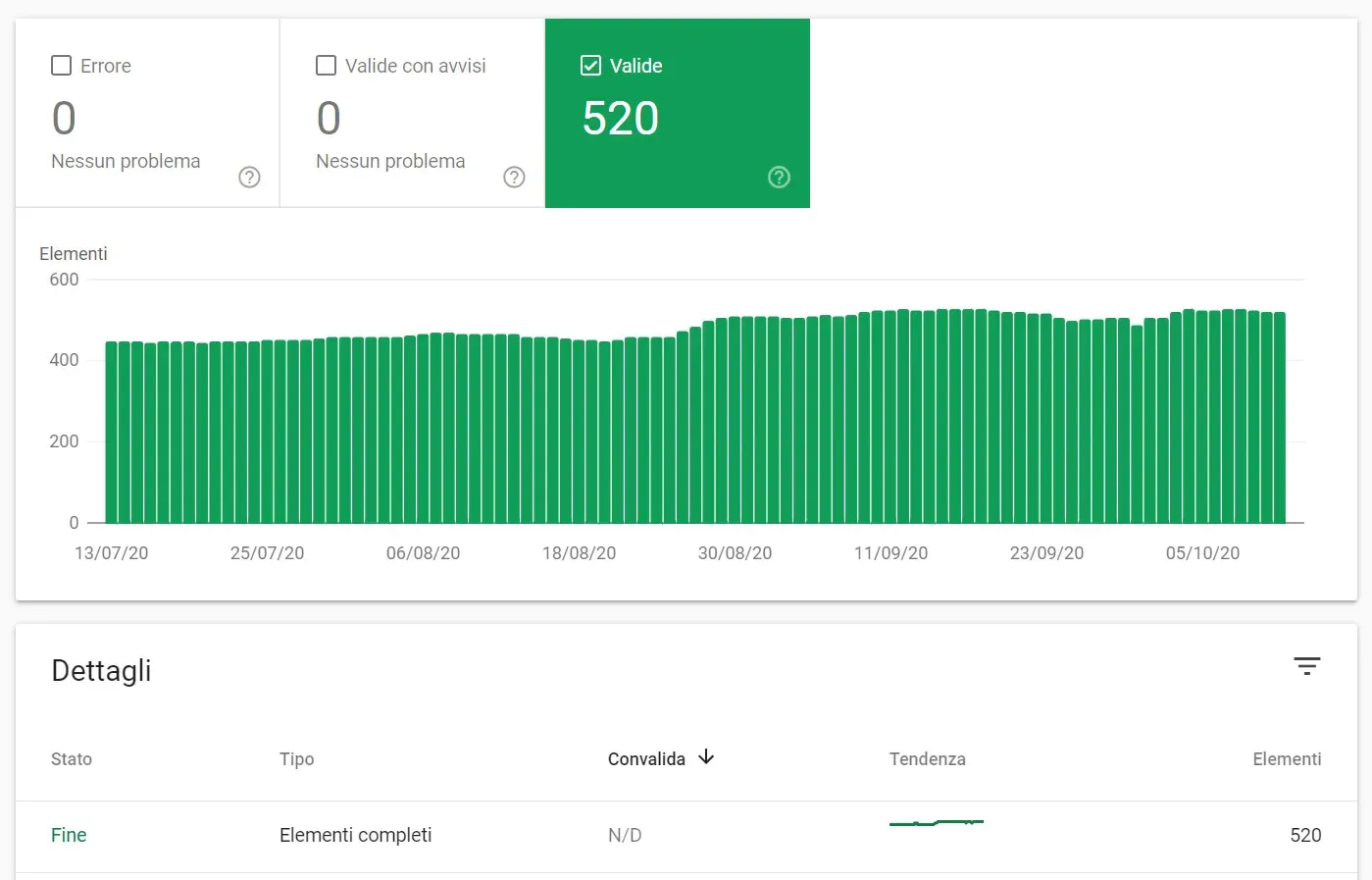
Mentre qui di seguito possiamo vedere che i dati strutturati di una scheda prodotto di un ecommerce non sono completi ed è necessario intervenire per correggerli.
Conclusioni
Questo è tutto quello che c'è da sapere per iniziare a lavorare con i dati strutturati.
Ricapitolando, abbiamo visto:
- Cosa sono i dati strutturati
- La documentazione ufficiale
- Come Google usa i dati strutturati
- Come si implementano via codice e via plugin con WordPress
- Controllare la validità dei dati strutturati
- Monitorare la validità nel tempo con search console
Se ci sono dubbi o domande scrivimi pure e non dimenticare di iscriverti al canale YouTube.
Foto di copertina di @pietrozj
Caricamento...
Diventiamo amici di penna? ✒️
Iscriviti alla newsletter per ricevere una mail ogni paio di settimane con le ultime novità, gli ultimi approfondimenti e gli ultimi corsi gratuiti puubblicati. Ogni tanto potrei scrivere qualcosa di commerciale, ma solo se mi autorizzi, altrimenti non ti disturberò oltre.
Se non ti piace la newsletter ti ricordo la community su Discord, dove puoi chiedere aiuto, fare domande e condividere le tue esperienze (ma soprattutto scambiare due meme con me). Ti aspetto!